

Top 20 C++ multithreading mistakes and how to avoid them
🧵 Top 20 C++ Multithreading Mistakes
A comprehensive guide to avoiding common pitfalls in concurrent C++ programming
Threading is one of the most complicated things to get right in programming, especially in C++. I’ve made a number of mistakes myself over the years. Most of these mistakes were luckily caught in code review and testing; however, some arcane ones did slip through and make it into production code and we had to patch live systems, which is always expensive.
🆕 2026 Update: This article has been completely refreshed for modern C++, including std::jthread (C++20), std::scoped_lock (C++17), improved std::atomic guidance, and fixes for common misconceptions. All code examples now follow modern best practices.
Not using join() to wait for background threads before terminating an application
If we forget to join a thread or detach it (make it unjoinable) before the main program terminates, it’ll cause a program crash.
#include <iostream>
#include <thread>
void LaunchRocket()
{
std::cout << "Launching Rocket" << std::endl;
}
int main()
{
std::thread t1(LaunchRocket);
// t1.join(); // Forgot to join - will cause a crash!
return 0;
}Why does it crash? At the end of main, thread t1 goes out of scope and the thread destructor is called. Inside the destructor, a check is performed to see if thread t1 is joinable. A joinable thread is a thread that has not been detached. If the thread is joinable, we call std::terminate. Here’s what the MSVC++ compiler does:
// MSVC++ thread destructor
~thread() _NOEXCEPT
{ // clean up
if (joinable())
_XSTD terminate();
}There are several ways to fix this depending on your needs:
Either join the thread to wait for it to complete, or detach it to let it run as a daemon:
int main()
{
std::thread t1(LaunchRocket);
t1.join(); // Wait for thread
return 0;
}int main()
{
std::thread t1(LaunchRocket);
t1.detach(); // Run as daemon
return 0;
}std::jthread automatically joins on destruction, eliminating this entire class of bugs!
#include <thread>
int main()
{
std::jthread t1(LaunchRocket); // Auto-joins on destruction!
return 0;
} // t1 automatically joined here - no crash!Bonus: std::jthread also supports cooperative cancellation via std::stop_token.
Trying to join a thread that has been previously detached
If you have detached a thread, you cannot rejoin it to the main thread. This is a very obvious error – what makes it problematic is that sometimes you might detach a thread and then write another few hundred lines of code and then try to join the same thread. After all, who remembers what they wrote 300 lines back, right?
The problem is that this won’t cause a compilation error (which would have been nice!); instead it’ll crash your program.
#include <iostream>
#include <thread>
void LaunchRocket()
{
std::cout << "Launching Rocket" << std::endl;
}
int main()
{
std::thread t1(LaunchRocket);
t1.detach();
//..... 100 lines of code
t1.join(); // CRASH !!!
return 0;
}int main()
{
std::thread t1(LaunchRocket);
t1.detach();
//..... 100 lines of code
if (t1.joinable())
{
t1.join();
}
return 0;
}std::jthread cannot be detached in the traditional sense, and always auto-joins. This eliminates the detach/join confusion entirely.
Not realizing that std::thread::join() blocks the calling thread
Calling join() on worker threads in your main/UI thread can cause the application to freeze. In GUI applications, consider using message-based communication instead.
In GUI applications, have worker threads post messages to the UI thread’s message loop instead of using blocking joins. This is why Microsoft’s WinRT platform made nearly all user-visible operations asynchronous.
Thinking that thread function arguments are pass by reference by default
Thread function arguments are pass by value by default. If you need changes persisted, use std::ref().
void increment(int& x) { x++; }
int value = 0;
thread t(increment, value);
// value is still 0!void increment(int& x) { x++; }
int value = 0;
thread t(increment, std::ref(value));
// value is now 1!Not protecting shared data or shared resources with a critical section
In a multithreaded environment, more than one thread is often competing for a resource or shared data. This often results in undefined behavior for the resource or data, unless the resource or data is protected using some mechanism that only allows ONE thread to act on it at a time.
In the example below, std::cout is a shared resource that is shared by 6 threads (t1-t5 + main).
#include <iostream>
#include <string>
#include <thread>
void CallHome(const std::string& message)
{
// Multiple threads writing to cout = garbled output!
std::cout << "Thread " << std::this_thread::get_id()
<< " says " << message << std::endl;
}
int main()
{
std::thread t1(CallHome, "Hello from Jupiter");
std::thread t2(CallHome, "Hello from Pluto");
std::thread t3(CallHome, "Hello from Moon");
CallHome("Hello from Main/Earth");
std::thread t4(CallHome, "Hello from Uranus");
std::thread t5(CallHome, "Hello from Neptune");
t1.join(); t2.join(); t3.join();
t4.join(); t5.join();
return 0;
}If we run the program above, we get garbled, interleaved output. This is because the five threads get the std::cout resource in a random fashion:
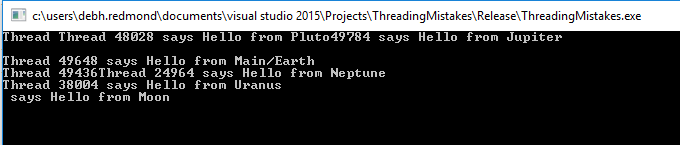
Output without mutex protection – notice the interleaved text
To make the output deterministic, protect access to std::cout using a std::mutex:
std::mutex mu; // Global or accessible to all threads
void CallHome(const std::string& message)
{
mu.lock();
std::cout << "Thread " << std::this_thread::get_id()
<< " says " << message << std::endl;
mu.unlock();
}Forgetting to release locks after a critical section
Calling lock() and unlock() on mutex directly is not preferable because you might forget to relinquish a lock that you’re holding. What happens then? All the other threads that are waiting on that resource will be blocked indefinitely and the program might hang.
In our toy example, if we forget to unlock the mutex in CallHome function, we’ll print out the first message from thread t1 and then the program will hang. This is because thread t1 gets hold of the mutex and all the other threads are essentially waiting to acquire the mutex.
void CallHome(const std::string& message)
{
mu.lock();
std::cout << "Thread " << std::this_thread::get_id()
<< " says " << message << std::endl;
//mu.unlock(); ASSUMING WE FORGOT TO RELEASE THE LOCK
}The program will hang on the console screen and not terminate:

Program hangs indefinitely when lock is not released
Programming errors happen, and for this reason it is never preferable to use the lock/unlock syntax on a mutex directly. Instead, use RAII-style lock wrappers that automatically release on destruction.
void CallHome(const std::string& message)
{
std::lock_guard<std::mutex> lock(mu); // Acquire the mutex
std::cout << "Thread " << std::this_thread::get_id()
<< " says " << message << std::endl;
} // lock_guard destroyed - mutex automatically releasedstd::scoped_lock is the modern replacement. It can also lock multiple mutexes atomically without deadlock:
// Single mutex (same as lock_guard)
std::scoped_lock lock(mu);
// Multiple mutexes - acquired atomically, no deadlock risk!
std::scoped_lock lock(mutex1, mutex2, mutex3);Not keeping critical sections as compact and small as possible
While one thread is in a critical section, all other threads are blocked. Keep critical sections minimal!
void CallHome(string msg)
{
std::lock_guard<std::mutex> lock(mu);
ReadFiftyThousandRecords(); // 10 sec!
cout << msg << endl;
}void CallHome(string msg)
{
ReadFiftyThousandRecords(); // Outside lock
std::lock_guard<std::mutex> lock(mu);
cout << msg << endl; // Only this needs protection
}Not acquiring multiple locks in the same order
This is one of the most common causes of DEADLOCK—a situation where threads block indefinitely because they are waiting to acquire access to resources currently locked by other blocked threads.
| Thread 1 | Thread 2 |
|---|---|
| Lock A ✓ | Lock B ✓ |
| Try Lock B ⏳ (blocked) | Try Lock A ⏳ (blocked) |
| 💀 DEADLOCK! | |
In some situations, when Thread 1 tries to acquire Lock B, it gets blocked because Thread 2 is already holding Lock B. And from Thread 2's perspective, it is blocked on acquiring Lock A, but cannot do so because Thread 1 is holding Lock A. Thread 1 cannot release Lock A unless it has acquired Lock B and so on. In other words, your program is hanged at this point.
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
std::mutex muA;
std::mutex muB;
void CallHome_AB(const std::string& message)
{
muA.lock(); // Acquires A first
std::this_thread::sleep_for(std::chrono::milliseconds(100));
muB.lock(); // Then tries to acquire B
std::cout << "Thread " << std::this_thread::get_id()
<< " says " << message << std::endl;
muB.unlock();
muA.unlock();
}
void CallHome_BA(const std::string& message)
{
muB.lock(); // Acquires B first
std::this_thread::sleep_for(std::chrono::milliseconds(100));
muA.lock(); // Then tries to acquire A - DEADLOCK!
std::cout << "Thread " << std::this_thread::get_id()
<< " says " << message << std::endl;
muA.unlock();
muB.unlock();
}
int main()
{
std::thread t1(CallHome_AB, "Hello from Jupiter");
std::thread t2(CallHome_BA, "Hello from Pluto");
t1.join();
t2.join();
return 0;
}If you run this, it will hang. Break into the debugger and look at the threads window to see the deadlock in action:
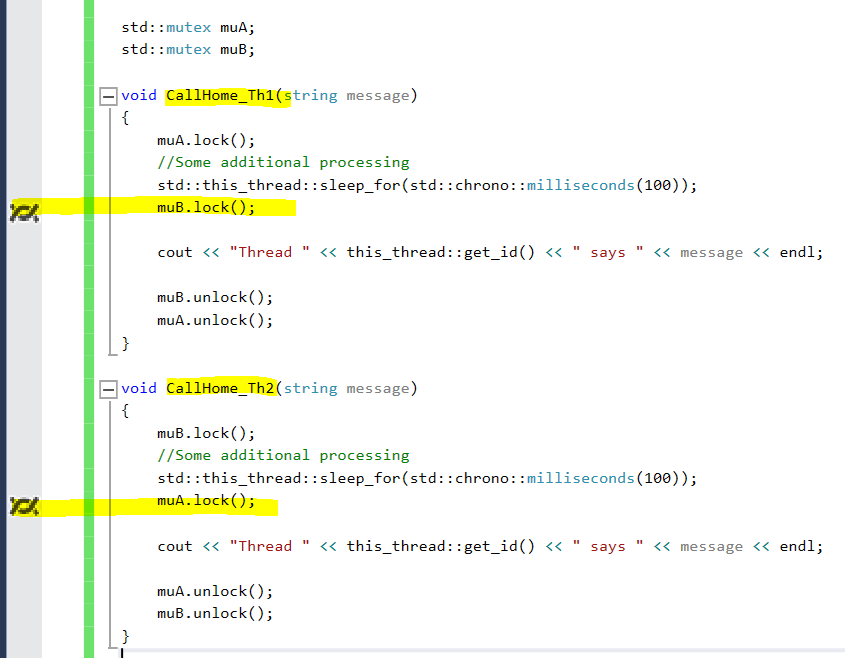
Visual Studio debugger showing Thread 1 waiting for mutex B while Thread 2 waits for mutex A
Establish a global ordering for all mutexes and always acquire them in that order.
std::scoped_lock uses a deadlock-avoidance algorithm to acquire multiple locks atomically:
void CallHome(const std::string& message)
{
// Acquires both mutexes atomically - no deadlock possible!
std::scoped_lock lock(muA, muB);
std::cout << "Thread " << std::this_thread::get_id()
<< " says " << message << std::endl;
} // Both mutexes released automaticallyIf you can't restructure the code, use try_lock_for() with a timeout to detect and recover from potential deadlocks.
Trying to acquire a std::mutex twice
Trying to acquire a mutex twice will cause undefined behavior. In most debug implementations, it'll likely result in a crash. What's interesting is that there will be no issue in the normal code path – the problem will only happen when the exception codepath is triggered.
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mu;
static int counter = 0;
void StartThruster()
{
try
{
// Some operation to start thruster
}
catch (...)
{
std::lock_guard<std::mutex> lock(mu); // Tries to lock AGAIN!
std::cout << "Launching rocket" << std::endl;
}
}
void LaunchRocket()
{
std::lock_guard<std::mutex> lock(mu); // First lock acquired here
counter++;
StartThruster(); // Calls function that also tries to lock!
}
int main()
{
std::thread t1(LaunchRocket);
t1.join();
return 0;
}Structure your code so it does not try to acquire a previously locked mutex. A superficial solution might be to use std::recursive_mutex — but this is almost always indicative of a bad design.
Using mutexes when std::atomic types will suffice
For simple data types like counters or flags, std::atomic often provides better performance than mutex locking because it uses CPU-level atomic instructions instead of OS-level locks.
int counter;
std::mutex mu;
...
mu.lock();
counter++;
mu.unlock();std::atomic<int> counter{0};
...
counter++; // Thread-safe!
counter.fetch_add(1); // Explicit version- Memory ordering matters: By default, atomics use
memory_order_seq_cst(strongest guarantees, most expensive). For simple counters,memory_order_relaxedmay suffice and is much faster. - Contention matters: Under high contention (many threads hammering the same atomic), a mutex with backoff may actually perform better than a spinning atomic.
- Compound operations: Atomics only guarantee individual operations are atomic.
if (flag) { doSomething(); }is NOT atomic even with atomic flag.
// Relaxed ordering - faster for simple counters
counter.fetch_add(1, std::memory_order_relaxed);
// Compare-and-swap for conditional updates
int expected = 0;
counter.compare_exchange_strong(expected, 1);Creating and destroying a lot of threads directly when a thread pool is available
Creating and deleting threads is expensive. Use thread pools for routine tasks like logging or network I/O.
- Threads are pre-allocated and reused
- No oversubscription concerns
- Thread lifecycle managed automatically
Popular libraries: Intel TBB, Microsoft PPL, std::async (built-in)
- C++17:
std::executionpolicies for parallel algorithms (std::for_each(std::execution::par, ...)) - C++20:
std::jthreadwith cooperative cancellation - C++23: Improved executors and sender/receiver model (in progress)
Not handling exceptions in background threads
Exceptions thrown in one thread cannot be caught in another thread. If we execute a throwing function in a separate thread and expect to catch the exception in main, it won't work—the program will crash.
void LaunchRocket()
{
throw std::runtime_error("Catch me in MAIN");
}
int main()
{
try
{
std::thread t1(LaunchRocket);
t1.join();
}
catch (const std::exception& ex)
{
// This will NOT catch the exception from t1!
std::cout << "Exception: " << ex.what() << std::endl;
}
return 0; // CRASH - uncaught exception in thread!
}std::exception_ptr threadException = nullptr;
void LaunchRocket()
{
try {
throw std::runtime_error("Houston, we have a problem");
}
catch (...) {
threadException = std::current_exception();
}
}
int main()
{
std::thread t1(LaunchRocket);
t1.join();
if (threadException) {
try {
std::rethrow_exception(threadException);
} catch (const std::exception& ex) {
std::cout << "Thread exception: " << ex.what() << std::endl;
}
}
}This is the cleaner, thread-safe approach designed exactly for this purpose:
#include <future>
void LaunchRocket(std::promise<void>& promise)
{
try {
// Do work...
throw std::runtime_error("Houston, we have a problem");
promise.set_value(); // Signal success
}
catch (...) {
promise.set_exception(std::current_exception());
}
}
int main()
{
std::promise<void> promise;
std::future<void> future = promise.get_future();
std::thread t1(LaunchRocket, std::ref(promise));
try {
future.get(); // Throws if exception was set
} catch (const std::exception& ex) {
std::cout << "Thread exception: " << ex.what() << std::endl;
}
t1.join();
}If you don't need manual thread control, std::async handles exception propagation automatically:
auto future = std::async(std::launch::async, []() {
throw std::runtime_error("Problem!");
});
try {
future.get(); // Exception automatically propagated here
} catch (const std::exception& ex) {
std::cout << "Caught: " << ex.what() << std::endl;
}Using threads to simulate async jobs when std::async will do
If you just need code executed asynchronously, std::async is simpler and safer than managing threads directly.
- No manual thread lifecycle management
- Easy result retrieval via
std::future - Reduces deadlock risk
- 14x less expensive than creating a thread (per Kurt Guntheroth)
std::future<int> result = std::async(&ConjureMagic);
// ... do other work ...
int value = result.get(); // Get the resultNot using std::launch::async if asynchronicity is desired
By default, std::async may run the task deferred (synchronously on .get()), not truly async!
auto future = std::async(myFunction);
// Might be deferred!auto future = std::async(
std::launch::async,
myFunction
);Calling .get() on a std::future in a time-sensitive code path
The following code retrieves the result from the future returned by an async task. However, the while loop will be blocked until the async task finishes (10 seconds in this case). If you consider this as a loop which renders data on screen, it can lead to a very bad user experience.
int main()
{
std::future<int> myFuture = std::async(std::launch::async, []()
{
std::this_thread::sleep_for(std::chrono::seconds(10));
return 8;
});
// Update Loop for rendering data
while (true)
{
std::cout << "Rendering Data" << std::endl;
int val = myFuture.get(); // This BLOCKS for 10 seconds!
// Do some processing with val
}
return 0;
}Note: There is an additional problem with the code above – it tries to poll a future a second time when it has no shared state, because the state of the future was already retrieved on the first iteration of the loop.
valid() only checks if the future has a shared state (hasn't been moved from or already consumed). It does NOT check if the result is ready. The following code still blocks:
if (myFuture.valid())
{
int val = myFuture.get(); // STILL BLOCKS until ready!
}Check if the result is actually ready before calling get():
using namespace std::chrono_literals;
int main()
{
std::future<int> myFuture = std::async(std::launch::async, []() {
std::this_thread::sleep_for(10s);
return 8;
});
bool resultReady = false;
int result = 0;
// Non-blocking render loop
while (true)
{
std::cout << "Rendering Data" << std::endl;
// Non-blocking check: is the future ready?
if (!resultReady && myFuture.valid())
{
if (myFuture.wait_for(0s) == std::future_status::ready)
{
result = myFuture.get(); // Non-blocking now!
resultReady = true;
std::cout << "Got result: " << result << std::endl;
}
}
// Continue rendering without blocking...
}
}Not realizing that exceptions thrown in async tasks propagate when .get() is called
If an async task throws an exception, it is stored and only propagated when you call .get() on the future. If .get() is not called, the exception is ignored and discarded when the future goes out of scope.
int main()
{
std::future<int> myFuture = std::async(std::launch::async, []()
{
throw std::runtime_error("Catch me in MAIN");
return 8;
});
// Exception is rethrown here - if uncaught, program terminates!
int result = myFuture.get();
return 0;
}Note: This doesn't "crash" in the traditional sense—the exception is catchable. But if you don't catch it, std::terminate is called.
If your async tasks can throw, you should always wrap the call to std::future::get() in a try/catch block:
int main()
{
std::future<int> myFuture = std::async(std::launch::async, []()
{
throw std::runtime_error("Catch me in MAIN");
return 8;
});
try
{
int result = myFuture.get();
std::cout << "Result: " << result << std::endl;
}
catch (const std::exception& e)
{
std::cout << "Async task threw: " << e.what() << std::endl;
}
return 0;
}Using std::async when you need granular control over thread execution
While std::async should suffice in most cases, there are situations where you'd want more granular control over the thread executing your code. For example, if you want to pin the thread to a specific CPU core in a multi-processor system (like Xbox, etc.).
This is made possible by using the native_handle of the std::thread, and passing it to a Win32 thread API function. There's a bunch of other functionality exposed via the Win32 Threads API that is not exposed in std::thread or std::async.
#include <windows.h>
#include <iostream>
#include <thread>
void LaunchRocket()
{
std::cout << "Launching Rocket" << std::endl;
}
int main()
{
std::thread t1(LaunchRocket);
// Pin thread to CPU core 5 (Windows example)
DWORD result = ::SetThreadIdealProcessor(t1.native_handle(), 5);
t1.join();
return 0;
}Another option is to create a std::packaged_task and move it to the desired thread of execution after setting thread properties.
Creating many more "runnable" threads than available cores
Threads can be classified into two types from a design perspective:
- Runnable threads consume 100% of the CPU time of the core on which they run. When more than one runnable thread is scheduled on a single core, they effectively time-slice the CPU time. There is no performance gain achieved – in fact there is performance degradation due to additional context switches.
- Waitable threads consume only a few cycles while waiting for events or network I/O. This leaves majority of the available compute time unused. That's why it's beneficial to schedule multiple waitable threads on a single core.
unsigned int cores = std::thread::hardware_concurrency();
// Returns the number of concurrent threads supported by the implementation
// This will factor in hyperthreading if availableRule of thumb for a quad-core system:
- Use 1 core for ALL waitable threads
- Use remaining 3 cores for runnable threads
Depending on your thread scheduler's efficiency, a few of your runnable threads might get context switched out (due to page faults, etc.) leaving the core idle for some amount of time. If you observe this during profiling, you should create a few more runnable threads than the number of your cores and tune it for your system.
Using "volatile" keyword for synchronization
The volatile keyword does NOT make operations atomic or thread-safe in standard C++! It only prevents the compiler from optimizing away reads/writes—it says nothing about hardware memory ordering or atomicity.
volatile int counter = 0;
counter++; // NOT atomic! Still a race condition
volatile bool ready = false;
while (!ready) {} // May not see updates from other threads!std::atomic<int> counter{0};
counter++; // Thread-safe!
std::atomic<bool> ready{false};
while (!ready.load()) {} // Correctly synchronizedMicrosoft's MSVC compiler historically gave volatile acquire/release semantics as a non-standard extension (when compiling with /volatile:ms). This is not portable! Code relying on this will break on GCC, Clang, or when MSVC is set to /volatile:iso (the standard-conforming mode). Always use std::atomic for portable code.
Using a lock-free architecture unless absolutely needed
There is something about complexity that appeals to every engineer. Lock-free programming sounds very sexy when compared to regular synchronization mechanisms such as mutex, condition variables, async, etc. However, every seasoned C++ developer I've spoken to has had the opinion that using lock-free programming as first resort is a form of premature optimization that can come back to haunt you at the most inopportune time (Think: a crash in production when you don't have the full heap dump!).
In my C++ career, there has been only one piece of tech which needed the performance of lock-free code because we were on a resource-constrained system where each transaction from our component needed to take no more than 10 microseconds.
- Have you considered designing your system such that it does not need a synchronization mechanism? The best synchronization is often "No synchronization"!
- If you do need synchronization, have you profiled your code to understand the performance characteristics? If yes, have you tried to optimize the hot code paths?
- Can you scale out instead of scaling up?
For regular application development, please consider lock-free programming only when you've exhausted all other alternatives.
Another way to look at it: if you're still making some of the above 19 mistakes, you should probably stay away from lock-free programming! 🙂
Quick Reference: All 20 Mistakes at a Glance
| # | Mistake | Fix | Modern C++ Solution |
|---|---|---|---|
| 1 | 🔴 Not joining/detaching threads | Always join() or detach() | std::jthread (C++20) |
| 2 | 🔴 Joining detached thread | Check joinable() first | std::jthread (C++20) |
| 3 | 🟡 Blocking UI with join() | Use async messaging | std::async + callbacks |
| 4 | 🟢 Args pass by value | Use std::ref() |
— |
| 5 | 🔴 Unprotected shared data | Use mutex | std::scoped_lock (C++17) |
| 6 | 🔴 Forgetting to unlock | Use RAII locks | std::scoped_lock (C++17) |
| 7 | 🟢 Large critical sections | Minimize locked code | — |
| 8 | 🔴 Wrong lock order → deadlock | Consistent lock ordering | std::scoped_lock (C++17) |
| 9 | 🔴 Double-locking mutex | Restructure code | — |
| 10 | 🟢 Mutex for simple types | Use std::atomic |
Consider memory_order |
| 11 | 🟢 Creating too many threads | Use thread pool | TBB, PPL, std::async |
| 12 | 🔴 Unhandled thread exceptions | Use exception_ptr | std::promise / std::async |
| 13 | 🟢 Manual threads for async | Use std::async |
std::async |
| 14 | 🟡 Default async policy | Use std::launch::async |
— |
| 15 | 🟡 Blocking .get() in loops | Use wait_for(0s) |
— |
| 16 | 🔴 Unhandled async exceptions | try/catch around get() | — |
| 17 | 🟢 async for low-level control | Use native_handle() | — |
| 18 | 🟢 Too many runnable threads | Use hardware_concurrency() | — |
| 19 | 🔴 volatile for sync | Use std::atomic |
— |
| 20 | 🟡 Premature lock-free | Profile first! | — |
- C++20: Use
std::jthreadinstead ofstd::thread— auto-joining eliminates mistakes #1 and #2 - C++17: Use
std::scoped_lockinstead ofstd::lock_guard— handles multiple locks atomically - C++17: Use
std::shared_mutexfor read-heavy workloads with occasional writes - Always: Prefer
std::asyncover manual thread management when possible - Always: Use
std::atomicfor simple shared state, but understand memory ordering
Frequently Asked Questions
What is the difference between std::thread and std::jthread?
std::jthread (C++20) automatically joins on destruction and supports cooperative cancellation via std::stop_token. Unlike std::thread, forgetting to join won't crash your program.
When should I use std::atomic vs std::mutex?
Use std::atomic for simple types (counters, flags) with single operations. Use std::mutex when you need to protect compound operations or complex data structures. Under high contention, mutex may actually perform better.
How do I prevent deadlocks in C++?
Use std::scoped_lock (C++17) to acquire multiple locks atomically, always acquire locks in a consistent order, or use std::timed_mutex with timeouts to detect and recover from deadlocks.
Is volatile thread-safe in C++?
No! Unlike Java, volatile in C++ provides no thread-safety guarantees. It only prevents compiler optimizations. Always use std::atomic for thread-safe access to shared variables.
What's the best way to handle exceptions in threads?
Use std::async which automatically propagates exceptions to the calling thread via the future. Alternatively, use std::promise to manually transfer exceptions between threads.